Bash Script ile MongoDB'den Elasticsearch'e Log Yazma
Bu dökümanın amacı, Apinizer Manager üzerinden Administration>Gateway Environments sayfasındaki ortamlarda, herhangi bir log connector'e Failover yöntemi olarak Mongodb gösterildiği ve burada biriken logların Administration>Analytics>Migrate Unsent API Traffic Logs sayfasından tekrar ilgili log kaynağına gönderim işleminde sorun yaşanması durumunda MongoDB'deki ilgili koleksiyondan gönderilemeyen bu trafik loglarını bir bash script ile göndermektir.
Bash script'in, log kaybı yaşanmaması için aşamalı olarak çalıştırılması ve veri tutan koleksiyon hakkında bilgi sahibi olunması önemlidir. Şemanın yapısını anlamak, gönderilemeyen logların ilgili log kaynağına başarılı bir şekilde aktarılması sürecinde kritik rol oynar.
Bu dokümanda log kaynağı Elasticsearch olarak ilerlenmiştir.
Bash Script Erişim Gereksinimleri
Bash script mongodb primary sunucusunda çalıştırılacaktır ve MongoDB primary sunucusunun Elasticsearch sunucusunun 9200 portuna erişim iznine sahip olması gerekmektedir.
Bash Script Paket Gereksinimleri
Bash script, JSON verilerini ayrıştırma işlemleri için jq paketini kullanmaktadır. jq paketinin kurulu olup olmadığını kontrol etmek için aşağıdaki komut çalıştırılabilir:
jq --version
Eğer jq paket yüklü değilse:
# Red Hat tabanlı sistemler için
sudo dnf install jqata
# Debian tabanlı sistemler için
sudo apt-get update sudo apt-get install jq
jq paketi, çoğu güncel Linux dağıtımının varsayılan depolarında bulunduğundan, güncel sunucularda çevrimdışı olsalar dahi bu komutlarla kurulabilmektedir.
Dikkat Edilmesi Gerekenler
Bash script çalıştırılırken, log verilerinin büyüklüğüne bağlı olarak MongoDB üzerinde yoğun işlem yükü oluşabilir. Bu durum, özellikle bellek (RAM) kullanımı üzerinde artışa sebep olabilir. Olası performans sorunlarının önüne geçmek için, script çalışırken sunucu kaynaklarını düzenli olarak aşağıdaki komutlarla kontrol etmek önemlidir:
free -g
systemctl status mongod.service
Eğer RAM kullanımı yüksek veya MongoDB servisi durma belirtileri gösterirse, script'i durdurup kaynak kullanımını incelemeniz ve gerekirse MongoDB yapılandırmasını ya da log gönderimini optimize etmeniz önerilir.
1) Mongodb Veritabanı Koleksiyonu Ön Çalışması
MongoDB veritabanına bağlanarak ilgili koleksiyon hakkında aşağıdaki bilgilerin alınması gerekmektedir:
Koleksiyon Adı: Elasticsearch'e gönderilmesi gereken koleksiyonun adı belirlenmelidir (Apinizer versiyonuna göre UnsentMessage veya log_UnsentMessage). Bu koleksiyon, apinizerdb veritabanında yer alan ve verilerin alınıp Elasticsearch'e aktarılacak koleksiyon olmalıdır.
Döküman Sayısı: Koleksiyondaki toplam döküman sayısı, Elasticsearch'e aktarılacak veri miktarını anlamanızı sağlar. Bu, veritabanı büyüklüğünü de göz önünde bulundurmanız için önemlidir.
Koleksiyon Boyutu: Koleksiyonun toplam boyutu, verinin ne kadar büyük olduğunu ve aktarım süresi ile performans üzerinde nasıl bir etki yapabileceğini belirlemek için kullanılır.
Veri Formatı ve Şema Kontrolü: Koleksiyondaki dökümanların formatı, Elasticsearch'e doğru şekilde aktarılabilmesi için kontrol edilmelidir. Gerekirse, verinin dönüştürülmesi veya şemanın uyumlu hale getirilmesi gerekebilir.
Bu bilgileri toplamak, sürecin doğru bir şekilde ilerlemesini ve olası sorunları önceden görmenizi sağlar.
mongosh mongodb://localhost:25080 --authenticationDatabase "admin" -u "<USERNAME>" -p "<PASSWORD>"
// Veritabanlarındaki tüm veritabanlarını gösterir.
show dbs
// apinizerdb veritabanını seçer.
use apinizerdb
// apinizerdb veritabanındaki koleksiyonları gösterir.
show collections
// 'UnsentMessage' koleksiyonundaki toplam döküman sayısını kontrol eder.
db.UnsentMessage.countDocuments({})
// 'UnsentMessage' koleksiyonunun depolama boyutunu MB cinsinden hesaplar.
db.UnsentMessage.stats().storageSize / (1024 * 1024).toFixed(2)
// Çalışma öncesi UnsentMessage ve log_UnsentMessage koleksiyonları hariç yedek alınır.
sudo mongodump --host <IP_ADDRESS> --port 25080 --excludeCollection UnsentMessage --excludeCollection log_UnsentMessage -d apinizerdb --authenticationDatabase "admin" -u apinizer -p <PASSWORD> --gzip --archive=<DIRECTORY>/apinizer-backup-d<DATE>-v<APINIZER_VERSION>--1.archive2) MongoDb'den Elasticsearch'e Gönderilecek Dökümanların Elasticsearch'de Mevcut Olup Olmadığı Kontrol Edilir
MongoDB’den Elasticsearch’e loglar aktarılmadan önce, Apinizer Correlation ID (aci) değerleri UnsentMessage koleksiyonunda baştan ve sondan bir döküman alınarak test edilir.
Retrieving Log Data from MongoDB
vi mongo_test.sh
mongo mongodb://<MONGO_IP>:25080 --authenticationDatabase "admin" -u "apinizer" -p
# Mongo versiyonu 6 ve yukarısıysa aşağıdaki komut çalıştırılır.
mongosh mongodb://<MONGO_IP>:25080 --authenticationDatabase "admin" -u "apinizer" -p
use apinizerdb
# İlk dökümanın aci değerini almak için
db.UnsentMessage.find({}, { content: 1, _id: 0 }).sort({ _id: 1 }).limit(1).forEach((doc) => { print(JSON.parse(doc.content).aci);});
# Son dökümanın aci değerini almak için
db.UnsentMessage.find({}, { content: 1, _id: 0 }).sort({ _id: -1 }).limit(1).forEach((doc) => { print(JSON.parse(doc.content).aci);});Elasticsearch’te Logların Kontrolü
İlk dökümanın ve son dökümanın ACI değerleri, Apinizer arayüzü üzerinden Elasticsearch’te olup olmadığı kontrol edilerek doğrulanır.
Bu noktada, ilgili ACI değerlerinin tüm environment'larda, tüm projelerde ve geniş bir zaman aralığında kontrol edilmesi gerekmektedir.
3) Loglar Elasticsearch'te Bulunmuyorsa Öncelikle Sınırlı Sayıda Veri Taşınarak Test Edilir
Bu bölümde asıl çalıştıracağımız scripti küçük bir veri setiyle sağlıklı şekilde çalışıp çalışmadığını kontrol etmek amacıyla çalıştırıyoruz.
Belirlenen miktarda log, Elasticsearch'e yazılıp ardından MongoDB'den silinir. Silinen dökümanlar, Elasticsearch'e yazılamama ihtimaline karşı bir dosyaya kaydedilir. Ayrıca, ACI değerleri ayrı bir dosyada saklanarak, Apinizer üzerinden log'ların Elasticsearch'te olup olmadığı kontrol edilir.
Eğer loglar başarıyla Elasticsearch'e yazıldıysa, bir sonraki aşamaya geçilebilir.
Dosya Yapısının Oluşturulması
Öncelikle, bash script’inin çalışacağı dizin oluşturulur ve gerekli dosyalar hazırlanır:
mkdir mongo-to-elastic-test
cd mongo-to-elastic-test/
touch aci.txt data.json yedek.json mongo_test_log.txt mongo_test.sh
chmod +x mongo_test.shvi mongo_test.sh
MONGO_URI="mongodb://<MONGO_USER>:<MONGO_USER_PASSWORD>@<MONGO_IP>:25080/admin?replicaSet=apinizer-replicaset"
MONGO_DB="apinizerdb"
MONGO_COLLECTION="UnsentMessage"
TEST_SIZE=150
ES_URL="http://<ELASTIC_IP>:9200"
ES_INDEX="<ELASTIC_DATA_STREAM_INDEX>(apinizer-log-apiproxy-exampleIndex)"
data=$(mongo "$MONGO_URI" --quiet --eval "JSON.stringify(db.getSiblingDB('$MONGO_DB').$MONGO_COLLECTION.find({}, {'_id': 1, 'content': 1}).limit($TEST_SIZE).toArray())" | grep -vE "I\s+(NETWORK|CONNPOOL|ReplicaSetMonitor|js)")
# If Mongo version is 6 and above, data is retrieved as follows.
# data=$(mongosh "$MONGO_URI" --quiet --eval "JSON.stringify(db.getSiblingDB('$MONGO_DB').$MONGO_COLLECTION.find({}, {'_id': 1, 'content': 1}).limit($TEST_SIZE).toArray())")
delete_ids=()
for row in $(echo "$data" | jq -r '.[] | @base64'); do
# Decode the base64 encoded row and extract _id and content
_id=$(echo $row | base64 --decode | jq -r '._id["$oid"]')
content=$(echo $row | base64 --decode | jq -r '.content')
aci_value=$(echo "$content" | jq -r '.aci')
echo "İşlenen ID: $_id, ACI Değeri: $aci_value" >> aci.txt
# Save content to file
echo "$content" > <DIRECTORY>/mongo-to-elastic-test/data.json
echo "$row" >> <DIRECTORY>/mongo-to-elastic-test/yedek.json
# Send data to Elasticsearch
response=$(curl -s -X POST "$ES_URL/$ES_INDEX/_doc" -H "Content-Type: application/json" --data-binary @<DIRECTORY>/mongo-to-elastic-test/data.json)
# Extract successful shard count from the response
successful=$(echo "$response" | jq -r '._shards.successful')
if [ "$successful" -eq 1 ]; then
delete_ids+=("$_id")
fi
done
# Create the ids_string for the delete operation in MongoDB
ids_string=$(printf "ObjectId(\"%s\"), " "${delete_ids[@]}" | sed 's/, $//') # Removing trailing comma
# Perform deletion from MongoDB
if [ ${#delete_ids[@]} -gt 0 ]; then
mongo "$MONGO_URI" --quiet --eval "db.getSiblingDB('$MONGO_DB').$MONGO_COLLECTION.deleteMany({ '_id': { \$in: [$ids_string] } })"
# If Mongo version 6 and above, the data is deleted as follows.
# mongosh "$MONGO_URI" --quiet --eval "db.getSiblingDB('$MONGO_DB').$MONGO_COLLECTION.deleteMany({ '_id': { \$in: [$ids_string] } })"
echo "Silme işlemi başarılı!"
fiScript’in Çalıştırılması
Script, aşağıdaki komutla arka planda çalıştırılır:
nohup bash <DIRECTORY>/mongo_test.sh > mongo_test_log.txt 2>&1 &
ps aux | grep <PROCESS_ID>Elasticsearch’te Logların Kontrolü
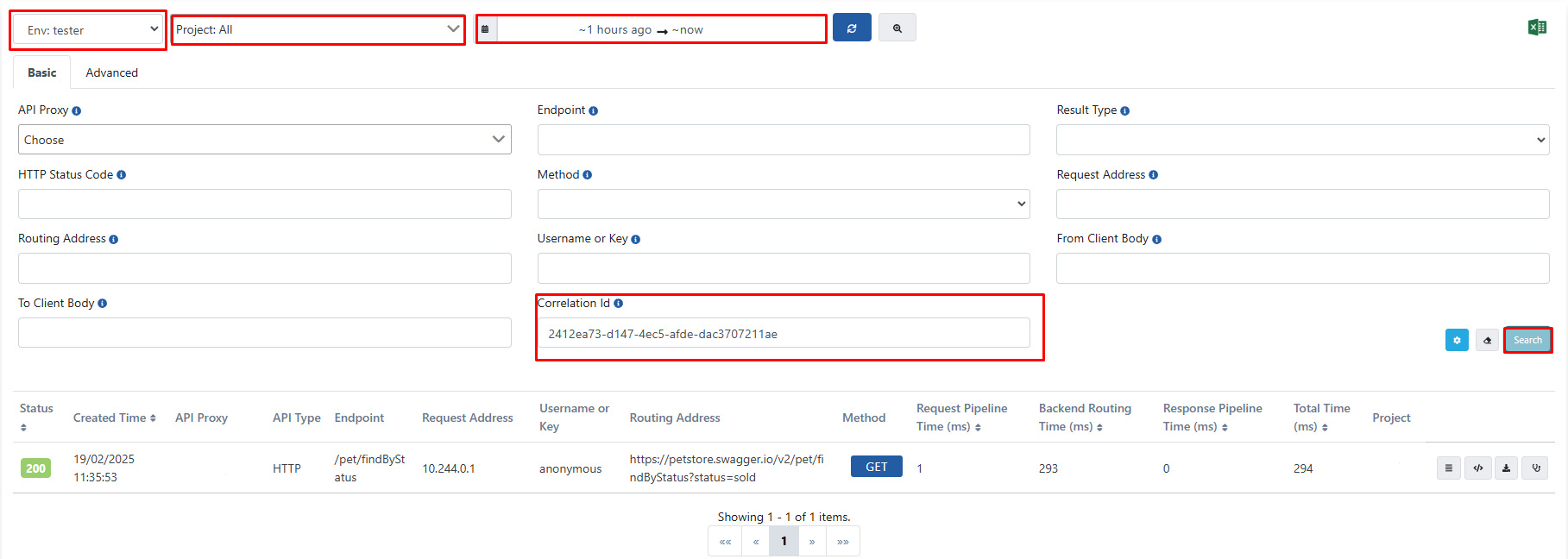
Script çalıştırıldıktan sonra aci.txt dosyasında listelenen ACI değerleri, Apinizer arayüzü üzerinden Elasticsearch’te olup olmadığı kontrol edilerek doğrulanır.
Bu noktada, ilgili ACI değerlerinin tüm environment'larda, tüm projelerde ve geniş bir zaman aralığında kontrol edilmesi gerekmektedir. Ve ACI değerleri girildiği zaman aşağıdaki görseldeki gibi ilgili logların gelmesi gerekmektedir.
4) Asıl script
Buraya verilerin sadece failover olarak mongodb'ye yazılıp yazılmadığını ve bunları elasticsearch'e geri gönderilip gönderilmediğini kontrol ettik.
Aşağıdaki Bash script’i, MongoDB’den verileri 1000’er batch’ler halinde alarak Elasticsearch’e yazılmasını ve başarıyla aktarılan verilerin MongoDB’den silinmesini sağlar.
Script içerisinde bulunan TOTAL_BATCHES parametresi, UnsentMessage veya log_UnsentMessage koleksiyonlarındaki toplam döküman sayısına göre ayarlanmalıdır. TOTAL_BATCHES × 1000 formülüyle işlenecek toplam veri miktarı belirlenir.
Dosya Yapısının Oluşturulması
Öncelikle, bash script’inin çalışacağı dizin oluşturulur ve gerekli dosyalar hazırlanır:
mkdir mongo-to-elastic
cd mongo-to-elastic/
touch data.json mongo_to_elastic_log.txt mongo_to_elastic.sh
chmod +x mongo_to_elastic.shMONGO_URI="mongodb://<MONGO_USER>:<MONGO_USER_PASSWORD>@<MONGO_IP>:25080/admin?replicaSet=apinizer-replicaset"
MONGO_DB="apinizerdb"
MONGO_COLLECTION="UnsentMessage"
ES_URL="http://<ELASTIC_IP>:9200"
ES_INDEX="<ELASTIC_DATA_STREAM_INDEX>(apinizer-log-apiproxy-exampleIndex)"
BATCH_SIZE=1000
TOTAL_BATCHES=<TOTAL_BATCHES = DOCUMENTSIZE / 1000>
for ((i=1; i<=TOTAL_BATCHES; i++)); do
data=$(mongo "$MONGO_URI" --quiet --eval "JSON.stringify(db.getSiblingDB('$MONGO_DB').$MONGO_COLLECTION.find({}, {'_id': 1, 'content': 1}).limit($BATCH_SIZE).toArray())" | grep -vE "I\s+(NETWORK|CONNPOOL|ReplicaSetMonitor|js)")
# If Mongo version is 6 and above, data is retrieved as follows.
# data=$(mongosh "$MONGO_URI" --quiet --eval "JSON.stringify(db.getSiblingDB('$MONGO_DB').$MONGO_COLLECTION.find({}, {'_id': 1, 'content': 1}).limit($BATCH_SIZE).toArray())")
delete_ids=()
for row in $(echo "$data" | jq -r '.[] | @base64'); do
# Decode the base64 encoded row and extract _id and content
_id=$(echo $row | base64 --decode | jq -r '._id["$oid"]')
content=$(echo $row | base64 --decode | jq -r '.content')
# Save content to file
echo "$content" > <DIRECTORY>/mongo-to-elastic/data.json
# Send data to Elasticsearch
response=$(curl -s -X POST "$ES_URL/$ES_INDEX/_doc" -H "Content-Type: application/json" --data-binary @<DIRECTORY>/mongo-to-elastic/data.json)
# Extract successful shard count from the response
successful=$(echo "$response" | jq -r '._shards.successful')
if [ "$successful" -eq 1 ]; then
delete_ids+=("$_id")
fi
done
# Create the ids_string for the delete operation in MongoDB
ids_string=$(printf "ObjectId(\"%s\"), " "${delete_ids[@]}" | sed 's/, $//') # Removing trailing comma
# Perform deletion from MongoDB
if [ ${#delete_ids[@]} -gt 0 ]; then
mongo "$MONGO_URI" --quiet --eval "db.getSiblingDB('$MONGO_DB').$MONGO_COLLECTION.deleteMany({ '_id': { \$in: [$ids_string] } })"
# If Mongo version 6 and above, the data is deleted as follows.
# mongosh "$MONGO_URI" --quiet --eval "db.getSiblingDB('$MONGO_DB').$MONGO_COLLECTION.deleteMany({ '_id': { \$in: [$ids_string] } })"
echo "Silme işlemi başarılı!"
fi
doneScript’in Çalıştırılması
Script, aşağıdaki komutla arka planda çalıştırılır:
nohup bash <DIRECTORY>/mongo_to_elastic.sh > mongo_to_elastic_log.txt 2>&1 &
ps aux | grep <PROCESS_ID>Script çalışırken, log dosyası kontrol edilmelidir. Eğer aşağıdaki gibi bir ifade log dosyasına sürekli ekleniyorsa script başarılı bir şekilde veri taşıma işlemi ilerlemektedir.
{ "acknowledged" : true, "deletedCount" : 1000 }Ayrıca, MongoDB üzerinden de kayıt sayıları kontrol edilerek log’ların taşınıp taşınmadığı doğrulanabilir.
mongo mongodb://<MONGO_IP>:25080 --authenticationDatabase "admin" -u "apinizer" -p
# Mongo versiyonu 6 ve yukarısıysa aşağıdaki komut çalıştırılır.
mongosh mongodb://<MONGO_IP>:25080 --authenticationDatabase "admin" -u "apinizer" -p
use apinizerdb
db.UnsentMessage.countDocuments({})5) Script ile İlgili Olası Hatalar ve Çözümler
1) Script'in Takılı Kalması veya Log Dosyasına Hiç Veri Yazmaması Durumu
Bu durum, MongoDB’den Elasticsearch’e veri aktaran komutun timeout'a uğraması sebebiyle gerçekleşebilir. Çözüm olarak, taşınması 2 saniyeden uzun süren MongoDB dökümanlarının _id değerleri timeout_ids dizisine kaydedilir. Böylece, sorunlu dökümanlar atlanarak aktarım işlemi devam ettirilir.
Aşağıdaki scriptte yapılan iyileştirmelerle bu sorun çözülür.
MONGO_URI="mongodb://<MONGO_USER>:<MONGO_USER_PASSWORD>@<MONGO_IP>:25080/admin?replicaSet=apinizer-replicaset"
MONGO_DB="apinizerdb"
MONGO_COLLECTION="UnsentMessage"
ES_URL="http://<ELASTIC_IP>:9200"
ES_INDEX="<ELASTIC_DATA_STREAM_INDEX>(apinizer-log-apiproxy-exampleIndex)"
BATCH_SIZE=1000
TOTAL_BATCHES=<TOTAL_BATCHES = DOCUMENTSIZE / 1000>
timeout_ids=()
for ((i=1; i<=TOTAL_BATCHES; i++)); do
if [ ${#timeout_ids[@]} -gt 0 ]; then
timeout_ids_json=$(printf "ObjectId(\"%s\"), " "${timeout_ids[@]}" | sed 's/, $//')
query="{'_id': { \$nin: [$timeout_ids_json] }}"
else
query="{}"
fi
data=$(mongo "$MONGO_URI" --quiet --eval "JSON.stringify(db.getSiblingDB('$MONGO_DB').$MONGO_COLLECTION.find($query,{'_id': 1, 'content': 1}).limit($BATCH_SIZE).toArray())" | grep -vE "I\s+(NETWORK|CONNPOOL|ReplicaSetMonitor|js)")
# If Mongo version is 6 and above, data is retrieved as follows.
# data=$(mongosh "$MONGO_URI" --quiet --eval "JSON.stringify(db.getSiblingDB('$MONGO_DB').$MONGO_COLLECTION.find($query, {'_id': 1, 'content': 1}).limit($BATCH_SIZE).toArray())")
delete_ids=()
for row in $(echo "$data" | jq -r '.[] | @base64'); do
# Decode the base64 encoded row and extract _id and content
_id=$(echo $row | base64 --decode | jq -r '._id["$oid"]')
content=$(echo $row | base64 --decode | jq -r '.content')
# Save content to file
echo "$content" > <DIRECTORY>/mongo-to-elastic/data.json
# Send data to Elasticsearch
response=$(curl -s -X POST "$ES_URL/$ES_INDEX/_doc" -H "Content-Type: application/json" --data-binary @<DIRECTORY>/mongo-to-elastic/data.json)
# Extract successful shard count from the response
successful=$(echo "$response" | jq -r '._shards.successful')
if [ "$successful" -eq 1 ]; then
delete_ids+=("$_id")
else
timeout_ids+=("$_id")
fi
done
# Perform deletion from MongoDB
if [ ${#delete_ids[@]} -gt 0 ]; then
ids_string=$(printf "ObjectId(\"%s\"), " "${delete_ids[@]}" | sed 's/, $//')
mongo "$MONGO_URI" --quiet --eval "db.getSiblingDB('$MONGO_DB').$MONGO_COLLECTION.deleteMany({ '_id': { \$in: [$ids_string] } })"
# If Mongo version 6 and above, the data is deleted as follows.
# mongosh "$MONGO_URI" --quiet --eval "db.getSiblingDB('$MONGO_DB').$MONGO_COLLECTION.deleteMany({ '_id': { \$in: [$ids_string] } })"
fi
done2) Script'in log dosyasında tcmalloc: large alloc 1073741824 bytes == 0x55f159412000 @ Hatası Varsa
Bu hata, batch ile alınan verilerin çok büyük olması nedeniyle bellekte aşırı yer kaplamasından kaynaklanır. Çözüm olarak, BATCH_SIZE değerini düşürmek gerekir. Örneğin, BATCH_SIZE 1000'den 10'a düşürülebilir:
3) Script'in log dosyasında mongo_to_elastic_log.txt: line 17: /usr/bin/mongo: Argument list too long Hatası Varsa
Bu hata, UnsentMessage koleksiyonundaki content alanlarının çok büyük olması nedeniyle oluşur. Komut satırında geçirilen argümanların boyutu sistem limitlerini aştığında bu hata meydana gelir. Büyük boyutlu verileri atlayarak scriptin çalışmaya devam etmesi sağlanabilir. Bunun için, belirli bir veri boyutunu atlamak üzere skip parametresi kullanılabilir:
data=$(mongo "$MONGO_URI" --quiet --eval "JSON.stringify(db.getSiblingDB('$MONGO_DB').$MONGO_COLLECTION.find($query,{'_id': 1, 'content': 1}).skip(<SKIP_DATA_SIZE>).limit($BATCH_SIZE).toArray())" | grep -vE "I\s+(NETWORK|CONNPOOL|ReplicaSetMonitor|js)")Eğer MongoDB 6 ve üstü bir sürüm kullanılıyorsa, mongosh komutunu kullanarak aynı işlem gerçekleştirilir.
6) Script Log Taşımasını Tamamladıktan Sonra MongoDB'de Disk Alanının Geri Kazanılması
Script, UnsentMessage koleksiyonundaki verileri Elasticsearch'e başarıyla taşıdıktan sonra, MongoDB'de gereksiz yer kaplayan boş alanları temizlemek ve disk kullanımını optimize etmek için compact işlemi gerçekleştirilmelidir.
mongosh mongodb://<MONGO_IP>:25080/apinizerdb --authenticationDatabase "admin" -u "apinizer" -p
db.runCommand({compact: "UnsentMessage"})Bu komut, UnsentMessage koleksiyonunun fiziksel depolama alanını yeniden düzenler. Özellikle büyük veri taşıma işlemlerinden sonra bu komutun mongodb secondary node üzerinde çalıştırılması önerilir.
Single node sistemlerde compact işlemi sırasında koleksiyon kilitleneceğinden, kullanım yoğun değilken veya veritabanın durması tolere edilebilecek iken çalıştırılması önerilir.