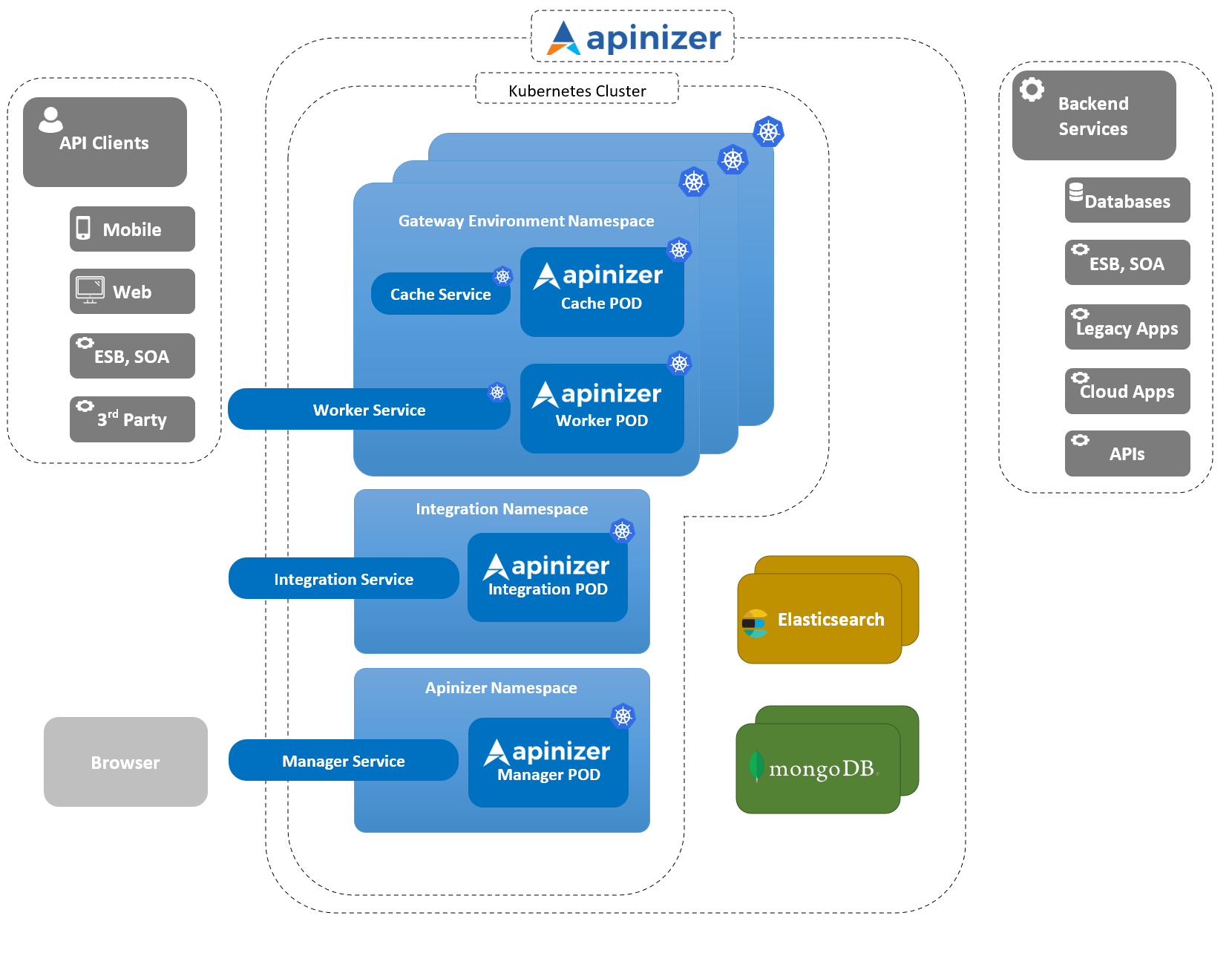
Architecture
In this section, the architectural structure of Apinizer is explained covering the layout of the components that make up the platform, their interactions with each other and their contents.
Modules and Components of the Apinizer Platform
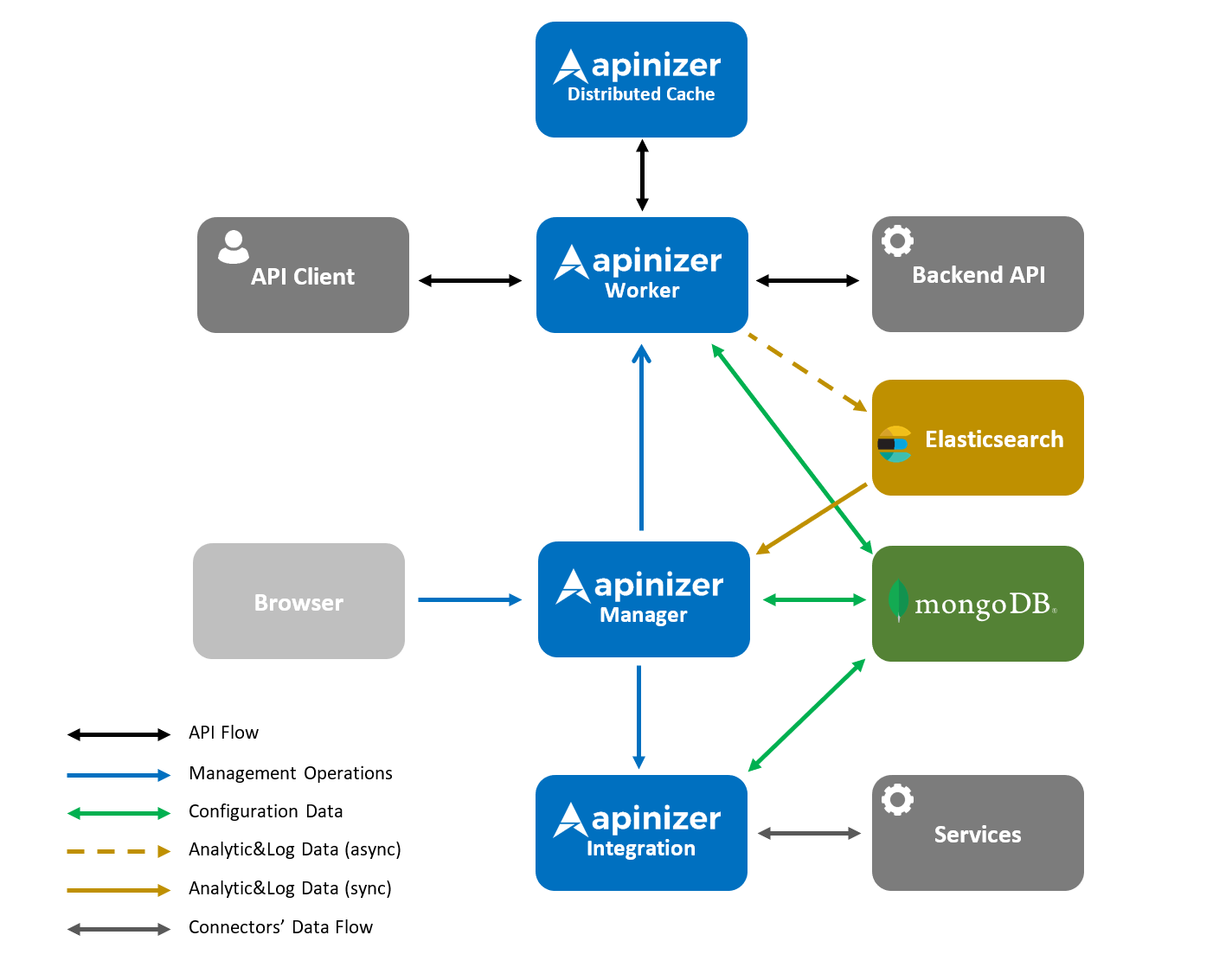
The following image shows the interaction of the modules within the Apinizer Platform:
The sub-components of these modules are given in the image below.
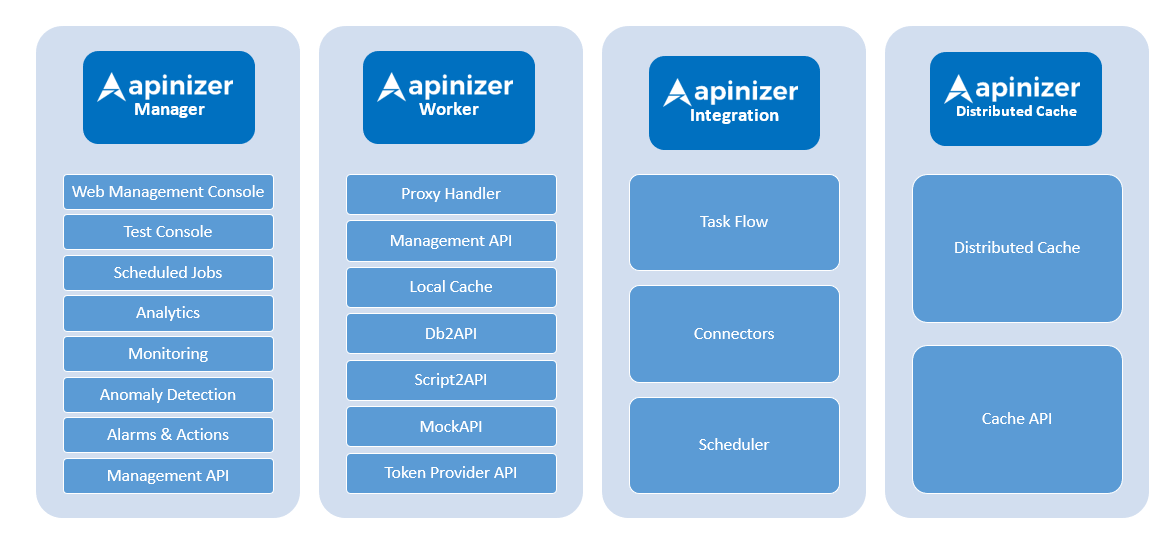
APINIZER MANAGER
There is one Manager module in the default settings in Apinizer. Although the Manager module seems to work mainly for configuration purposes, the tasks it runs on make it an important component of the system.
Web API Manager
It enables the settings/definitions to be made via form-based interfaces via a Web browser and to send these settings to other components.
Test Console
It is a test tool that can be used without leaving the development environment and without the need for any other software for testing internal or external APIs.
Scheduled Jobs
It manages the scheduled tasks.
Analytics
It provides visualization and querying of analytical data in the log records.
Monitoring
It checks whether the API Proxies work properly, and generates alarms in case they don't.
Anomaly Detection
It checks whether there is an abnormal situation in the operation of the API Proxies, and creates alarms in case there is.
Alarms & Actions
It enables the alarms generated by Monitoring or Anomaly Detection to be converted into action. For example, it sends the alarm data to the relevant persons by e-mail.
Management API
It allows the settings that can be made through the application to be made with APIs.
APINIZER WORKER
The Worker module is the most important component of Apinizer. Each Worker belongs to an Environment and its settings change according to the Environment in which it works. Apinizer can have multiple Environments and each Environment can have multiple Workers.
Proxy Handler
It is the point where requests from clients are fulfilled. It also acts as the Policy Enforcement Point. It processes the incoming request in accordance with the defined policies and directs it to the relevant Backend API/Service. It can work as a load balancer while routing. TLS/SSL termination is done here. It also processes the response returned from the Backend API/Service in accordance with the defined policies and sends it to the client. In the meantime, it records all transactions and sends it to the log server asynchronously. It handles the recording of sensitive data in accordance with the established rules (deletion, masking, encryption).
Management API
Deploying the configurations in the Apinizer Manager module to the Worker ensures that the installed ones are reloaded and updated (redeploy) or removed (undeploy). Not to be confused with the Management API in the Apinizer Manager module. All configurations to be deployed to the Worker come through the Management API.
Local Cache
All data loaded through the Management API is kept in Local Cache. Worker pulls its data from MongoDB database and puts it in Local Cache during boot or reboot.
Db-2-Api
It provides the execution of defined SQLs or the execution of Stored Procedures by connecting to a defined database. Access to Db-2-Api is via the Proxy Handler.
Script2API
It enables defined JavaScript or Groovy Scripts to be run. Access to Script2API is via the Proxy Handler.
Mock API
It allows returning pre-prepared responses based on defined conditions. Access to MockAPI is via the Proxy Handler.
Token Provider API
If OAuth2 or JWT Authorization Policies are desired to be used on Apinizer, Token Provider API running on Worker is used for token generation. The client sends its credentials to the Token Provider API, if the information is correct, Token is generated and returned to the client. The records related to the token request are recorded on the Log server. Thus, the information of who, when and which Token was given is kept. JWT Tokens do not need to be kept in the database due to their nature, their certificate is checked for verification. Tokens of type OAuth2 are also saved in the MongoDB database. It is also added to Apinizer Cache to improve the performance of Token check in Proxy Handler.
APINIZER CACHE
Apinizer not only manages the data shared by its components, but also provides performance improvement by storing it in a distributed cache.
Distributed Cache
As a distributed cache implementation, Apinizer is to use Hazelcast technology that can be easily expanded and scaled on Kubernetes, managed with dynamic configuration and successfully performed. Quota, Throttling, OAuth2 Token, Load Balancing Object etc. objects are kept and processed on the Distributed Cache.
Cache API
Cache API is used for all transactions to be made over the cache.
APINIZER INTEGRATION
With Apinizer Integrator, developers can create task chains to automate complex tasks spanning various resources and roll them out on demand via schedulers or by creating APIs. Thus, for example, there is no need to develop a program for a workflow such as transferring the central bank's rates to the specified local database in the desired format at the same time every day, calling a Web Service that will log it to another database after the job is completed, and notifying the specified people by sending an e-mail.
Connectors
It allows connecting to different sources, sending to or pulling data from these sources. For example; Mail, API Call, PagerDuty, Opsgenie, Oracle DB, Postgres, IBM DB2.. etc
Task Flow
It enables job definitions to be made using connectors. Defined tasks can be chained and the output of one task can be used as input to other tasks.
Scheduler
It enables the defined tasks or task chains to run automatically at a certain time.
Environment
An Environment in the Apinizer Platform is a virtual server area that API Proxies are deployed and published. It has its own access address and settings, and operates in isolation from other Environments and using resources such as CPU and RAM allocated to it.
It is recommended to use multiple Environments for two purposes:
- To manage the API lifecycle by creating Environments for different purposes such as Development, Test, Production.
- By grouping much resource-consuming APIs, to ensure that they work in isolation, thus preventing the performance of other APIs from being adversely affected.
API Proxies can be installed on one or more Environments (check Revision, Deploy, Redeploy, Undeploy for details).
The installed Environment or Environments are all located in a cluster and run on the servers where the Apinizer Platform is installed.
Environment Components
All Environments created on Apinizer Platform run on Kubernetes infrastructure.
An environment contains the following components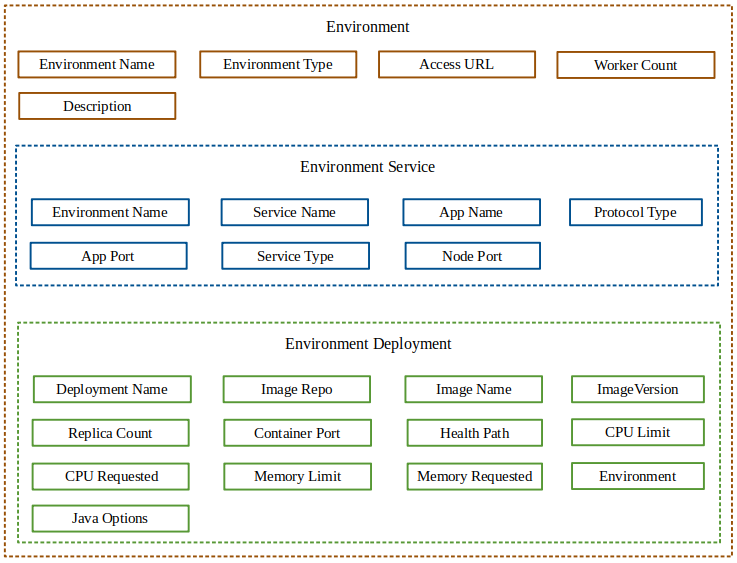
Environment corresponds to Namespace in the context of Kubernetes.
Kubernetes clusters can simultaneously manage large volumes of disconnected workloads. Kubernetes uses a concept called Namespace to de-clutter objects within the cluster.
Namespaces allow objects to be grouped together and filtered and controlled as a unit. Thus, it can be used for purposes such as applying customized access control policies or making groupings to separate all units from each other for a test environment.
The following image shows Apinizer's deployment on Kubernetes: