API yönetim platformlarında uçtan uca izleme, hem performans hem de operasyonel kararlılık açısından kritik bir gerekliliktir. Apinizer, Prometheus üzerinden yayınladığı zengin metrik kümesini, kurumların halihazırda kullandığı Zabbix izleme platformuyla entegre etmenize olanak tanır. Bu makale; Apinizer Gateway ve Cache bileşenlerinin metriklerini Prometheus aracılığıyla toplayıp Zabbix'te tek bir merkezde görselleştirmek, alarm yapılandırmak ve trend analizi yapmak için adım adım bir rehber sunar.
Apinizer'ın Metrik Sistemine Genel Bakış
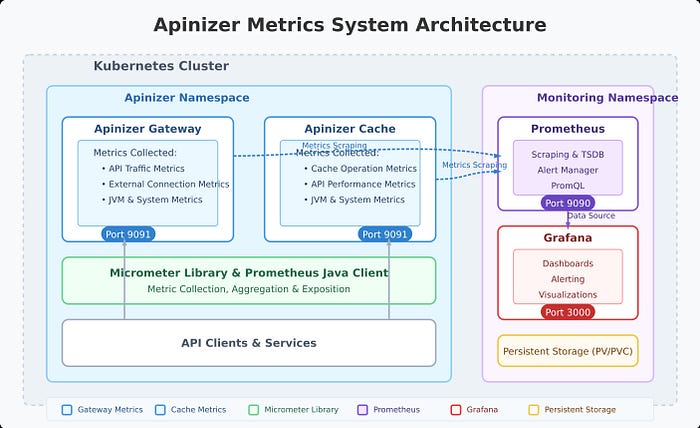
Apinizer'ın metrik sistemi Micrometer üzerine inşa edilmiştir ve Prometheus formatında metrik yayınlar. Platform, iki ana bileşen üzerinden geniş bir metrik yelpazesi toplar:
- Apinizer Gateway: API trafiği, harici bağlantılar, JVM sağlığı ve sistem kaynakları ile ilgili metrikleri toplar
- Apinizer Cache: Önbellek işlemlerini, API isteklerini, JVM performansını ve sistem sağlığını izler
Zabbix entegrasyonu, bu metrikleri HTTP Agent item tipi üzerinden Prometheus'un /api/v1/query REST API'sine sorgu atarak toplar. Böylece ek bir Zabbix-Prometheus eklentisi gerekmeden, mevcut Prometheus altyapınız Zabbix'in veri kaynağına dönüşür.
Apinizer Tarafından Toplanan Metrikler

Apinizer Gateway Metrikleri
Gateway bileşeni çeşitli kategorilerde metrikler toplar:
API Trafik Metrikleri
Bu metrikler Apinizer Gateway üzerinden geçen istekleri takip eder:
- Toplam API trafik istekleri
- Başarılı/başarısız/engellenen API istekleri
- İstek işleme süreleri (pipeline, yönlendirme, toplam)
- İstek ve yanıt boyutları
- Önbellek isabet istatistikleri
Her metrik iki formda mevcuttur:
- Toplam metrikler (örn., tüm API'ler genelinde toplam API istekleri)
- Detaylı boyutlara sahip etiketli metrikler (örn., API Kimliği, API adı başına istekler)
Harici Bağlantı Metrikleri
Bunlar harici servislere yapılan bağlantıları takip eder:
- Toplam harici istekler
- Harici hata sayısı
- Harici yanıt süreleri
JVM Metrikleri
Bunlar Java Sanal Makinesi hakkında içgörüler sağlar:
- Bellek kullanımı (heap, non-heap)
- Garbage collection istatistikleri
- Thread sayıları ve durumları
Sistem Metrikleri
Bunlar altta yatan sistemi izler:
- CPU kullanımı
- İşlemci sayısı
- Sistem yük ortalaması
- File descriptor sayıları
Apinizer Cache Metrikleri
Cache bileşeni şunları toplar:
Önbellek İşlem Metrikleri
- Önbellek get/put sayıları
- Önbellek boyutu ve giriş sayıları
- Önbellek işlem gecikmeleri
- Önbellek girişleri tarafından bellek kullanımı
API Metrikleri
- API istek sayıları
- API yanıt süreleri
- API hata sayıları
JVM ve Sistem Metrikleri
Gateway'e benzer şekilde, Cache bileşeni de JVM performansını ve sistem kaynak kullanımını takip eder.
Zabbix Entegrasyonunun Kurulumu
1. Apinizer Bileşenlerinde Metriklerin Etkinleştirilmesi
Apinizer Gateway için:
Worker deployment'ını düzenleyin ve METRICS_ENABLED=true ortam değişkenini ekleyin. Ayrıca container spec'e 9091 portu da eklenmelidir.
# Ortam değişkenini ekle
kubectl -n <namespace> set env deployment/worker METRICS_ENABLED=true
# Container port 9091'i ekle
kubectl -n <namespace> patch deployment worker --type=json -p='[
{
"op": "add",
"path": "/spec/template/spec/containers/0/ports/-",
"value": {"containerPort": 9091, "name": "metrics", "protocol": "TCP"}
}
]'
Apinizer Cache için:
Cache deployment'ını düzenleyin ve METRICS_ENABLED=TRUE ortam değişkenini ekleyin.
Kubernetes CLI üzerinden:
kubectl edit deploy -n <namespace> cache
# Aşağıdaki ortam değişkenini ekleyin
- name: METRICS_ENABLED
value: "true"
2. Prometheus'un Yapılandırılması
Apinizer pod'larının Prometheus tarafından scrape edilebilmesi için worker ve cache deployment'larına annotation'lar eklemeniz, Prometheus'un da bu pod'ları keşfedecek şekilde yapılandırılmış olması gerekir.
Pod annotation'ları ekleyin:
template:
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9091"
prometheus.io/path: "/metrics"
Prometheus scrape config'ini Apinizer namespace'lerini kapsayacak şekilde genişletin:
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_namespace]
action: keep
regex: tester|prod|uat # Apinizer'ın çalıştığı namespace'leri ekleyin
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_port, __meta_kubernetes_pod_ip]
action: replace
regex: (\d+);((([0-9]+?)(\.|$)){4})
replacement: $2:$1
target_label: __address__
Yapılandırma değişikliğinden sonra Prometheus'u yeniden başlatın:
kubectl -n monitoring rollout restart deployment/prometheus
3. Prometheus'un Zabbix'ten Erişilebilir Olması
Zabbix Server'ın Prometheus HTTP endpoint'ine erişebilmesi gerekir. En basit yöntem NodePort ile dışarı açmaktır:
apiVersion: v1
kind: Service
metadata:
name: prometheus-service
namespace: monitoring
spec:
type: NodePort
ports:
- port: 9090
targetPort: 9090
nodePort: 30190
selector:
app: prometheus
Zabbix Server'ından bağlantıyı doğrulayın:
curl -s http://<cluster-node-ip>:30190/-/healthy
# Beklenen: Prometheus Server is Healthy.
4. Zabbix Tarafının Hazırlanması
Zabbix Agent kurulumu
Apinizer'ın çalıştığı Kubernetes node'una Zabbix Agent kurun. Böylece host düzeyindeki metrikler (CPU, RAM, disk) Apinizer metrikleriyle birlikte toplanır:
wget https://repo.zabbix.com/zabbix/7.0/ubuntu/pool/main/z/zabbix-release/zabbix-release_7.0-2+ubuntu24.04_all.deb
dpkg -i zabbix-release_7.0-2+ubuntu24.04_all.deb
apt update && apt install -y zabbix-agent
# /etc/zabbix/zabbix_agentd.conf dosyasında:
# Server=<zabbix-server-ip>
# Hostname=<node-hostname>
systemctl enable --now zabbix-agent
Zabbix Template'ini import edin
Apinizer için hazırlanmış HTTP Agent tabanlı template (41 item, 8 trigger, 9 macro) Zabbix arayüzünden import edilir:
Data collection → Templates → Import menüsünden apinizer_by_prometheus.yaml dosyasını seçin. Advanced options altında tüm kategoriler için Update existing, Create new ve Delete missing seçeneklerini işaretleyip Import'a basın.
Host yaratın ve macro'ları yapılandırın
Apinizer ortamı için bir Zabbix host oluşturun:
- Host name:
<node-hostname>(Zabbix Agent ile aynı) - Templates:
Linux by Zabbix agentveApinizer by Prometheus - Macros (Inherited and host macros sekmesinden override edin):
{$PROM.URL}→http://<cluster-node-ip>:30190{$PROM.NAMESPACE}→tester(veya hedef namespace)
PromQL ile Apinizer Metriklerinin Analizi
Zabbix HTTP Agent item'ları, Prometheus'un /api/v1/query endpoint'ine PromQL sorgusu atar ve dönen JSON cevaptaki değeri JSONPath ile çıkartır. Aşağıdaki sorgular hem template'in dahili olarak kullandığı sorgulardır hem de Zabbix'te yeni bir item tanımlarken kullanabileceğiniz örneklerdir:
Gateway API Trafik Analizi
# Son 5 dakikadaki toplam API istek hızı
sum(rate(apinizer_api_traffic_total_count_total{application="apinizer"}[5m]))
# Başarılı istek oranı (%)
(sum(rate(apinizer_api_traffic_success_count_total{application="apinizer"}[5m])) / sum(rate(apinizer_api_traffic_total_count_total{application="apinizer"}[5m]))) * 100
# Ortalama yanıt süresi (milisaniye)
1000 * sum(rate(apinizer_api_traffic_total_time_seconds_sum{application="apinizer"}[5m])) / sum(rate(apinizer_api_traffic_total_time_seconds_count{application="apinizer"}[5m]))
Önbellek Performans Analizi
# Worker tarafından görülen cache işlem hata oranı
sum(rate(apinizer_cache_errors_total_count_total{application="apinizer"}[5m]))
# Cache pod'unun JVM heap kullanımı (%)
(sum(jvm_memory_used_bytes{application="apinizer-cache",area="heap"}) / sum(jvm_memory_max_bytes{application="apinizer-cache",area="heap"})) * 100
# Cache pod'unun thread sayısı
sum(jvm_threads_live_threads{application="apinizer-cache"})
JVM Analizi
# Worker'ın bellek kullanımı (%)
(sum(jvm_memory_used_bytes{application="apinizer",area="heap"}) / sum(jvm_memory_max_bytes{application="apinizer",area="heap"})) * 100
# Garbage collection süresi (saniye/saniye)
sum(rate(jvm_gc_pause_seconds_sum{application="apinizer"}[5m]))
Zabbix Dashboard'larının Oluşturulması
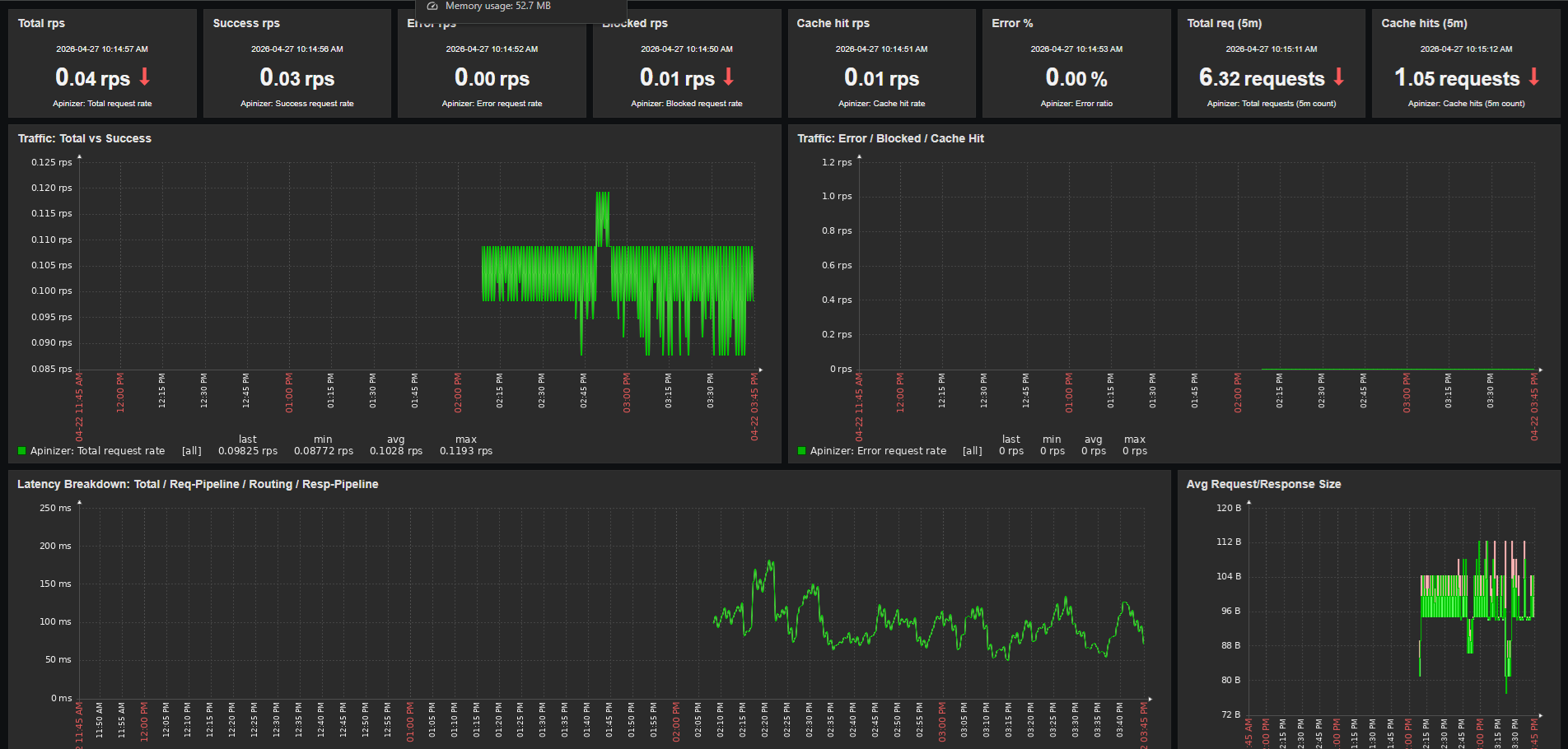
Zabbix dashboard'ları, dashboard.create API çağrısıyla tek seferde, Python script üzerinden oluşturulabilir. Hazır script ile 5 sayfa ve 72 widget'lık bir dashboard tek API çağrısında üretilir. Aşağıda her sayfa için içerikler özetlenmiştir.
Panel 1: Apinizer UP
- Item:
Apinizer apimanager availability(TCP service check) - Görselleştirme: Item value (1 = ayakta, 0 = down)
Panel 2: API Success Rate Gauge
- Metrik:
(sum(rate(apinizer_api_traffic_success_count_total[5m])) / sum(rate(apinizer_api_traffic_total_count_total[5m]))) * 100 - Görselleştirme: Gauge (yeşil 95+, sarı 90-95, kırmızı 90 altı)
Panel 3: API Blocked Rate Gauge
- Metrik: blocked / total * 100
- Görselleştirme: Gauge (sarı 10+, kırmızı 30+)
Panel 4: Cache Hit Rate Gauge
- Metrik: cache_hits / total * 100
- Görselleştirme: Gauge (mavi tonlamalı)
Panel 5: Request Rate Trend
- Metrikler: total / success / error / blocked rate'leri
- Görselleştirme: Graph (classic), 4 çizgi
Panel 6: Active Problems
- Host'a bağlı tüm aktif trigger'lar
- Görselleştirme: Problems widget
Traffic & Latency Sayfası
Panel 1: Latency Breakdown
- Metrikler:
- Total response time:
1000 * sum(rate(apinizer_api_traffic_total_time_seconds_sum[5m])) / sum(rate(apinizer_api_traffic_total_time_seconds_count[5m])) - Request pipeline: aynı formül
request_pipeline_time_secondsile - Routing: aynı formül
routing_time_secondsile - Response pipeline: aynı formül
response_pipeline_time_secondsile - Görselleştirme: Graph (classic), 4 çizgi
Panel 2: Request/Response Size
- İstek boyutu:
sum(rate(apinizer_api_traffic_request_size_bytes_sum[5m])) / sum(rate(apinizer_api_traffic_request_size_bytes_count[5m])) - Yanıt boyutu:
sum(rate(apinizer_api_traffic_response_size_bytes_sum[5m])) / sum(rate(apinizer_api_traffic_response_size_bytes_count[5m])) - Görselleştirme: Graph (classic)
Panel 3: 5dk Toplam İstek Sayısı
- Metrik:
sum(increase(apinizer_api_traffic_total_count_total[5m])) - Görselleştirme: Item value
JVM & Infrastructure Sayfası
Panel 1: JVM Heap %
- Metrik:
sum(jvm_memory_used_bytes{area="heap"}) / sum(jvm_memory_max_bytes{area="heap"}) * 100 - Görselleştirme: Gauge (sarı 70+, kırmızı 85+)
Panel 2: Heap Used (MB) - Çoklu Worker Karşılaştırması
- Metrik 1 (tester):
sum(jvm_memory_used_bytes{namespace="tester",application="apinizer",area="heap"}) / 1024 / 1024 - Metrik 2 (zwebsocket): aynı sorgu farklı namespace ile
- Görselleştirme: Graph (classic), 2 çizgi farklı renkte
Panel 3: GC Pause Rate
- Metrik:
sum(rate(jvm_gc_pause_seconds_sum[5m])) - Görselleştirme: Graph (classic)
Panel 4: HTTP Pool Utilization
- Metrik:
sum(httpcomponents_httpclient_pool_total_connections) / sum(httpcomponents_httpclient_pool_total_max) * 100 - Görselleştirme: Gauge
Panel 5: External (Backend) Request vs Error Rate
- Metrikler:
- Backend istek hızı:
sum(rate(apinizer_external_requests_total_count_total[5m])) - Backend hata hızı:
sum(rate(apinizer_external_errors_total_count_total[5m])) - Görselleştirme: Graph (classic)
Cache Pod Sayfası
Panel 1: Cache Pod Heap %
- Metrik:
sum(jvm_memory_used_bytes{application="apinizer-cache",area="heap"}) / sum(jvm_memory_max_bytes{application="apinizer-cache",area="heap"}) * 100 - Görselleştirme: Gauge
Panel 2: Cache Pod Threads
- Metrik:
sum(jvm_threads_live_threads{application="apinizer-cache"}) - Görselleştirme: Item value
Panel 3: Worker-side Cache Operasyon Hatası
- Metrik:
sum(rate(apinizer_cache_errors_total_count_total[5m])) - Görselleştirme: Graph (classic)
Host Sağlık Sayfası
Bu sayfa, Apinizer'ın çalıştığı Kubernetes node'unun OS düzeyindeki metriklerini gösterir. Veriler Linux by Zabbix agent template'inden gelir; Prometheus üzerinden değil, doğrudan Zabbix Agent'tan toplanır.
Panel 1: CPU Utilization
- Item: Linux template'in
system.cpu.utilitem'ı - Görselleştirme: Gauge ve Graph (classic)
Panel 2: Memory Utilization
- Item:
vm.memory.utilization - Görselleştirme: Gauge ve Graph (classic)
Panel 3: Load Average (1m)
- Item:
system.cpu.load[all,avg1] - Görselleştirme: Graph (classic)
Zabbix Trigger'ları (Alarm)
Apinizer template'i, varsayılan olarak 8 trigger ile gelir. Her trigger ayrı bir macro üzerinden eşik değerini alır, böylece host bazında özelleştirilebilir:
| Trigger | Varsayılan Eşik | Macro |
|---|---|---|
| Yüksek error oranı (5dk) | %5 | {$APINIZER.ERROR_RATIO.MAX} |
| Yüksek total response süresi (5dk) | 2000 ms | {$APINIZER.LATENCY.MAX} |
| Yüksek backend error oranı (5dk) | 1 rps | {$APINIZER.EXT_ERROR.MAX} |
| JVM heap doluluğu yüksek (5dk) | %85 | {$APINIZER.HEAP.MAX} |
| Yüksek GC baskıs�ı (5dk) | 0.1 s/s | {$APINIZER.GC.MAX} |
| HTTP pool doldu (5dk) | %90 | {$APINIZER.POOL.MAX} |
| Trafik metriği gelmiyor (nodata 5dk) | yok | (override yok) |
| Blocked request artışı (5dk) | 10 rps | {$APINIZER.BLOCKED.MAX} |
Trigger'lar tetiklendiğinde Zabbix'in Alerts → Actions → Trigger actions menüsünden e-posta, Slack, SMS, PagerDuty veya webhook bildirim kanalına yönlendirilebilir.
Best Practices
1. Metrik Saklama Süresi
Zabbix tarafında item başına history (ham veri) ve trends (saatlik agregasyon) süreleri ayrı yapılandırılır. Apinizer template'i varsayılan olarak şu değerleri kullanır:
- History: 30 gün
- Trends: 365 gün
Daha uzun saklama için Zabbix konfigürasyonunda history/trends partitionlarının yeterli depolama alanına sahip olduğundan emin olun. Prometheus tarafında ayrıca:
--storage.tsdb.path=/prometheus
--storage.tsdb.retention.time=15d
değerlerini ihtiyacınıza göre ayarlayın.
2. Çoklu Ortam (Multi-Environment) Yapılandırması
Apinizer birden fazla namespace'te çalıştığında (tester, uat, prod) her ortam için ayrı bir Zabbix host yaratın. Aynı Apinizer by Prometheus template'ini her host'a bağlayın ve {$PROM.NAMESPACE} macro'sunu host düzeyinde override ederek hedef namespace'i belirtin. Böylece:
- Her ortamın metrikleri birbirinden izole tutulur
- Her ortam için ayrı dashboard üretilebilir
- Trigger eşikleri ortam bazında farklılaştırılabilir (örn. prod'da error oranı %2, test'te %10)
3. Aynı Dashboard'da Çoklu Worker Karşılaştırması
İki worker'ı (örneğin canary release sırasında) aynı dashboard'da karşılaştırmak için, template'e ikinci worker namespace'ine işaret eden ek item'lar eklenir. JVM & Infrastructure sayfasındaki Heap, Threads, GC ve CPU grafiklerinde her iki worker'ın çizgisi farklı renklerde aynı grafiğe çizilir. Bu, performans karşılaştırması için en hızlı görsel yöntemdir.
4. Etiket (Label) Kullanımı
Apinizer'ın yaydığı her metric series şu label'ları taşır:
namespace— pod'un Kubernetes namespace'ipod— pod adı (restart'ta değişir)application— apinizer (worker) veya apinizer-cache (cache pod)environment— Apinizer'ın iç environment tanımlayıcısı
Zabbix item'larındaki PromQL sorgularında özellikle application="apinizer" filtresini kullanın; aksi halde sum() fonksiyonu worker ve cache metric'lerini birlikte toplar ve sonuç yanıltıcı olur.
Sonuç
Apinizer'ı Prometheus üzerinden Zabbix ile entegre etmek, kurumların halihazırda kullandığı operasyonel izleme platformunda Apinizer'a özel görünürlük kazandırır. Metrik toplama Prometheus tarafından yapılır; Zabbix HTTP Agent item'ları üzerinden bu metrikleri sorgulayarak kendi history/trends/dashboard/trigger ekosistemine dahil eder.
Bu entegrasyon her bileşenin güçlü yönlerinden yararlanır:
- Apinizer'ın kapsamlı metrik toplama özelliği
- Prometheus'un verimli zaman serisi veritabanı ve PromQL sorgu dili
- Zabbix'in olgun trigger, escalation ve bildirim yönlendirme yetenekleri
- Zabbix Agent'ın işletim sistemi düzeyindeki host metriklerini Apinizer metrikleriyle aynı dashboard'da birleştirme imkânı
Apinizer ortamınızı uçtan uca izlemeye başlamak için bugün entegrasyonu kurarak operasyonel veriyi tek merkezde toplayabilirsiniz.
Kaynaklar
Daha fazla bilgi için:
- Apinizer Dökümantasyonu
- Prometheus Dokümantasyonu
- Zabbix Dokümantasyonu