A Comprehensive Overview of Rate Limit, Throttling and Quota Management
In the dynamic world of API development and management, controlling the flow of incoming requests is essential to maintain system stability, ensure fair usage, and prevent abuse.
Apinizer offers easy-to-use, high-performance solutions to these challenges through its advanced rate limit, throttling, and quota management features.
In this article, we will examine these core concepts and explain how they are implemented in Apinizer.

Rate Limit and Throttling
Rate limit and throttling are often used interchangeably; both refer to the process of controlling the rate of requests reaching an API.
Time Scale: Typically measured in seconds or minutes.
Examples:
- 100 requests per second
- 1000 requests per minute
Implementation: Apinizer uses Distributed Cache to perform the relevant rule calculations, store results, and distribute them across different systems.
Data Storage: Cache-only. This means data is temporary and may be lost when the system restarts; for short-term limits this is acceptable.
Use Cases:
- Protecting APIs against sudden traffic spikes
- Ensuring fair usage among multiple clients in short time windows
- Preventing abuse or DoS attacks
Quota Management
Quota management works toward similar goals but operates on a different scale and with different objectives.
Time Scale: Typically measured in hours, days, or months.
Examples:
- 10,000 requests per day
- 1,000,000 requests per month
Implementation: Uses a combination of cache for fast access and real-time updates, and database for persistent long-term storage.
Data Storage:
- Cache: Primary source for real-time quota checks, updated synchronously with every API call.
- Database: Used as secondary, persistent storage. Updated asynchronously to reduce API response time; ensures data persistence when the system restarts or in case of cache failure.
Use Cases:
- Enforcing business-level API usage limits
- Billing and accounting for API consumption
- Long-term usage analysis and planning
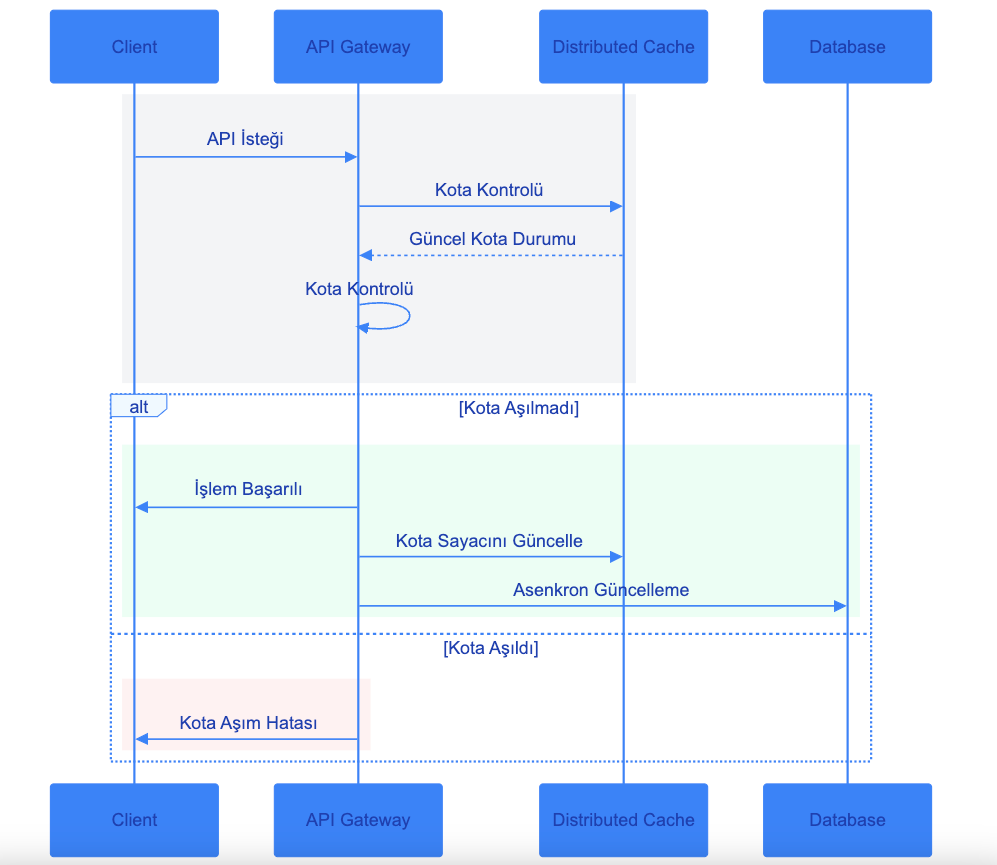
Throttling and Quota Management Workflow
A multi-layered approach is used to monitor and manage API usage quotas. This system operates through four main components: Client, API Gateway, Distributed Cache, and Database.
The flow works as follows:
-
Initial Request Check: Every API request from the client first passes through the API Gateway. The Gateway quickly consults the Distributed Cache to check whether the request is within quota.
-
Cache Layer: The Distributed Cache holds quota information with high performance and low latency. This layer is a critical component for fast system response. The current quota status from the cache is evaluated by the API Gateway.
-
Decision Mechanism: Based on the information from the cache, the API Gateway follows one of two paths:
- Success Scenario: If the quota limit has not been exceeded, the request is processed and a successful response is returned to the client. The quota counter is then updated.
- Failure Scenario: If the quota has been exceeded, the request is rejected and an appropriate error message is sent to the client.
-
Data Synchronization: For successful operations, quota information is updated in two stages:
- First, the Distributed Cache is updated quickly (synchronous)
- Then the database update is performed asynchronously
-
Durability and Consistency: The database ensures data continuity for long-term quota tracking and in case of system restarts. The asynchronous update approach guarantees data durability without affecting API performance.
This flow achieves an optimal balance between high performance and data consistency. Cache usage provides fast response times while database support guarantees data persistence. Asynchronous database updates offer reliable quota tracking while preserving system performance.
The following diagram summarizes this flow:
The Critical "Interval Window Type" Parameter
At the heart of both throttling and quota management logic is the Interval Window Type parameter.
This parameter determines how the time window in which requests are counted is managed and updated.
Possible Values
- Fixed Window
- Sliding Window
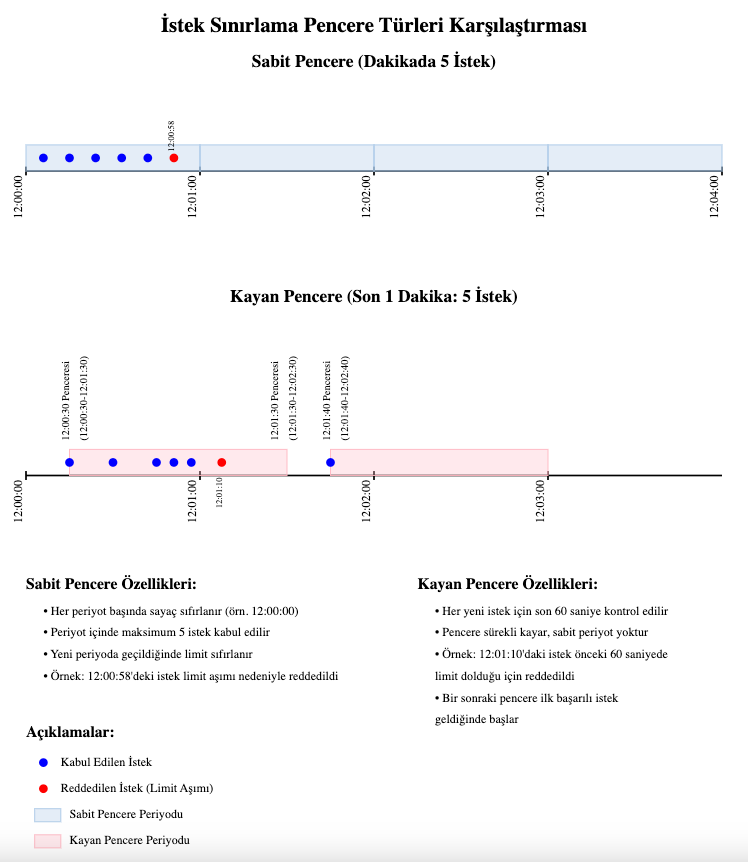
Fixed Window
In the Fixed Window approach, time is divided into fixed, non-overlapping periods.
Behavior:
- All requests within a given period are counted together.
- The counter is reset when each new period starts.
- The cache entry TTL (Time To Live) is set to the remaining time in the current period.
Example:
- If the period is set to 1 minute and starts at 12:00:00:
- Requests between 12:00:00 and 12:00:59 are counted in the same window.
- At 12:01:00 a new window starts and the counter is reset.
Sliding Window
In the Sliding Window approach, each request starts its own time window.
Behavior:
- The window "slides" with each new request.
- It counts all requests in the past period length and is continuously updated.
- The cache entry TTL is always set to the full period length.
Example:
- If the period is set to 1 minute:
- A request at 12:00:30 counts all requests between 11:59:30 and 12:00:30.
- A request at 12:00:45 counts all requests between 11:59:45 and 12:00:45.
Managing Longer Time Intervals
When working with longer time intervals, especially for quota management, fixed window calculations become more complex.
Here is how to manage different scenarios:
For Intervals Shorter Than One Day (e.g. 15 minutes, 12 hours)
Formula: Window Start = Day Start + (Elapsed Periods * Period Duration)
Example for a 15-minute period:
- Current time: 14:37
- Calculation:
- Day start: 00:00
- Elapsed 15-minute periods: 58
- Window start: 14:30
- This request belongs to the 14:30 - 14:44:59 window.
For Intervals of One Day or Longer (e.g. 3 days)
Formula: Window Start = Unix Epoch + (Elapsed Periods * Period Duration)
Example for a 3-day period:
- Current date: 2023-10-15
- Calculation:
- Days since Unix epoch: 19,645
- Elapsed 3-day intervals: 6,548 (19,645 / 3, rounded down)
- Window start: 2023-10-13 00:00:00
- This request belongs to the interval 2023-10-13 00:00:00 - 2023-10-15 23:59:59.
Note: Pay attention to setting the time zone value for managing day boundaries!
Flexible Limits with Dynamic Key Generation
An important feature in our rate limit, throttling, and quota implementation is the ability to dynamically generate restriction keys based on various aspects of the incoming request. This approach allows more granular and flexible control of API usage without complex code changes.
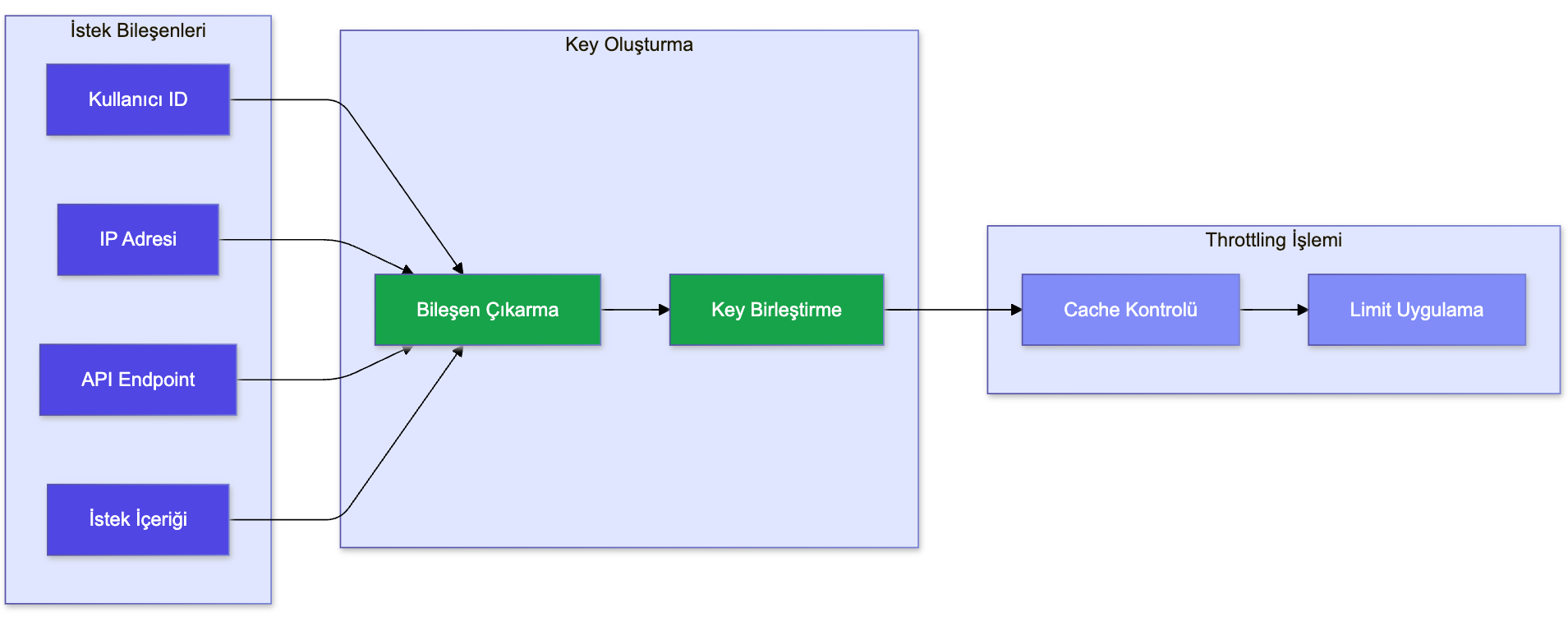
Here is an overview of how this is implemented in our current system:
-
Flexible Key Components: The system allows restriction keys to be built from any combination of:
- Credentials (e.g. user ID, API key)
- Request metadata (e.g. IP address, request headers)
- Content from the request payload
-
Dynamic Key Creation:
- The system dynamically reads the specified components on each request and builds the key.
- This reading is based on predefined paths or patterns defined in the configuration.
-
Key Combination:
- The extracted components are combined into a single string to form the restriction key.
- A consistent separator (e.g. "-") is used to distinguish different components in the key.
-
Scenario-Based Keys: This approach enables various restriction scenarios:
- Per-user limits: Using user ID as the key
- Per-endpoint limits: Combining API endpoint identity with user ID
- Content-based limits: Including specific fields from the request payload in the key
-
Scalability and Performance:
- The key generation process is designed to be lightweight and fast.
- Complex computations are avoided to minimize impact on request processing time.
-
Security Considerations:
- The system ensures that sensitive information is not exposed in the generated keys.
-
Consistency Across Services:
- This key generation logic is applied consistently across all API endpoints.
- It is typically implemented as a central service or utility that all endpoints can use.
By applying this flexible key generation approach, our system can adapt to various rate limiting and throttling requirements without code changes. Whether it is applying different limits for different types of operations, controlling access based on user roles, or implementing complex multi-factor restriction rules, the system can meet these needs through configuration changes only.
This level of flexibility allows fine-tuning API usage and enables businesses to enforce fair use policies, prevent abuse, and optimize resource allocation effectively. It also provides the ability to quickly adjust restriction strategies in response to changing business needs or observed usage patterns.
Conclusion
Effective API traffic control through request limiting, throttling, and quota management is essential for building robust, fair, and scalable API services. By understanding the nuances of fixed and sliding windows, applying appropriate time-scale strategies, and following best practices, you can keep your APIs performant, protected, and profitable.
Remember, the choice between request limiting strategies and Interval Window Type configuration should be based on your specific use case, traffic patterns, and business requirements. Regularly reviewing and tuning these parameters will help you achieve an optimal balance between protection and accessibility for your API services.